
The self-curation challenge for the future of AI
AI cannot grow without a radical change in strategy. Better data is a start.

I propose a self-curation challenge that will develop AI models able to make credibility judgments about their training resources, represent that credible information, and use it to support accurate performance. Current models have hit a practical limit on scaling and on performance improvement. The available data is now limited as are the computational resources. Further progress will require new kinds of models and the resolution of anthropogenic debt, where humans provide most of the intelligence by solving enough of a problem that simple computations can complete the task. Developing models that can independently assess the credibility of their training data will improve model accuracy and reduce anthropogenic debt. Although probably achievable in the short to medium term, self-curation will require some substantial model changes and enable increased performance accuracy.
Although many prognosticators predict that artificial general intelligence (AGI) will be achieved in the next few months, in fact, progress in artificial intelligence, driven by large language models (GenAI), has stalled. The most recently released models show small, questionable improvements at all. Current models have depended on scaling to improve. They have relied on exponential growth of compute resources and data, which has so far been possible because of untapped resources, but those resources cannot continue to grow at the required rate. Something else will need to be done to further improve the models and I propose a self-curation challenge to begin that process.
Limitations of GenAI
Satya Nadella has observed that “intelligence” grows with the log of compute, that is, with the computational capacity used to train the models. Each small step in model performance requires a multiplication of the available computational capacity. Each increment in model intelligence requires exponentially more computing resources. Another way of saying this is that the intelligence value of each added GPU (the main bottleneck in compute capacity) drops toward 0 as systems get larger
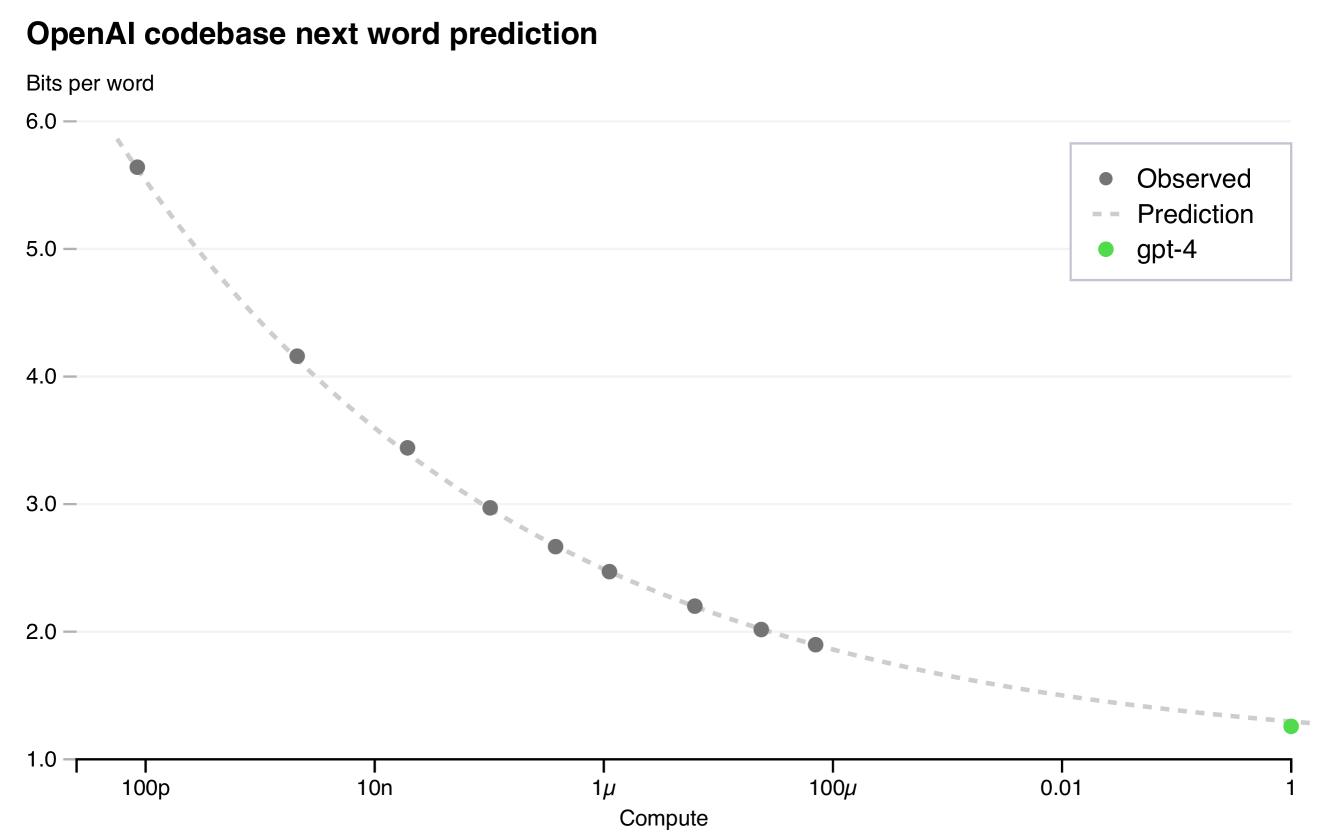
.
The technical report for GPT-4 reported that decreasing error by one bit, required a model that had 10,000 times the computational capacity of the previous model. They also showed that the curve relating their measure of intelligence to log compute was not uniformly proportional (as Nadella, claimed) but was slowing down. The earliest and smallest models showed an improvement of 1 bit when the model increased compute by 10 times. In the latest models each 10-fold multiplication of compute capacity yielded only about 0.16 bits of improvement. Following their curve, cutting the error rate by another bit would require multiplying the compute resources by 17 orders of magnitude. That is simply unachievable. Even another 10,000 x increase in computing would be challenging.
GPT-4 is said to have been trained on 25,000 GPUs. If the curve relating log compute capacity were straight, then reducing the remaining error by another bit would require 250 million GPUs. At the end of 2024, Microsoft, which hosts the GPT models, was estimated to have about 900,000 GPUs. They were also estimated to continue acquiring GPUs and that by the end of 2025, they were projected to have 3.1 million units. Even if the full set of GPUs were dedicated to OpenAI, they would still fall far short of the estimated number of required units to produce a marginally apparent improvement in the model represented in the figure above.
NVIDIA produced under 4 million data center GPUs in 2023, so they are unlikely to be able to produce enough to achieve that computational capability for many years. If OpenAI’s projected curve is correct, then a more realistic estimate would be 2,500,000,000,000,000,000,000 GPUs). The natural resources may not be available to support this level of production, and the resulting performance improvement may not be noticeable or economically significant.
Chip production grows linearly, not exponentially. So just from a hardware perspective, substantial improvements are unlikely to be forthcoming using the present approach. If AI is to be improved, it will have to take a different approach than what we are currently seeing. It will require methods, approaches, and capabilities that are not only unavailable; they are mostly unimagined at this point.
Another factor that severely limits the likelihood of improving AI or of ever achieving AGI in the foreseeable future is anthropogenic debt. The kind of intelligence attributed to current models depends strongly on human input to solve the truly difficult problems. In general, humans identify the problems to be pursued, identify the key variables to be used, provide the representations, including the state space, the loss function for assessing progress toward solution, the prompts, and many other tools. The computer models are mainly limited to adjusting the provided parameters, usually through gradient descent, to solve the final step. Once the human contribution is provided, all that is left is for the models execute conceptually simple “moves” to adjust the values of the provided parameters to meet the provided goal of the computation. Without this human contribution, the models could do nothing.
The need for human input and the role it plays in solving these problems is rarely acknowledged or reported. Models with this level of dependence on humans cannot be autonomous and cannot be generally intelligent. An AI model cannot achieve the goals of general intelligence until it can address the full “range [of problems] to which the human mind has been applied” (Simon & Newell, 1958), from inception to specification of the problem space to finding an appropriate solution and verifying it. The kinds of problems that humans now solve for AI must surely be within the range described by Simon and Newell.
The self-curation challenge
In an attempt to jumpstart the search for the tools that will be needed to improve AI, and to achieve AGI, I propose the self-curation challenge. This challenge is intended to begin addressing the anthropogenic debt that currently limits computational intelligence by finding methods that will help to make training these models more independent, effective, and efficient. Improving the quality of training data should help to improve performance and the development of a mechanism by which the computer can curate its own data should move the models at least a tiny step toward general intelligence. Meeting this challenge, thus, should provide both short-term and long-term benefits for current and future artificial intelligence, and I think that it is practically within reach.
The challenge: Develop a model that can identify and seek out quality information to use it for training, and to evaluate its own output.
Quality data should be credible and useful. The credibility of data is related to its truth. At a minimum it requires AI models to have some representation of the truthfulness of their data. Current models guess the probability of the next token to be produced, but this probability is related to the frequency with which each token occurred previously modified by the human feedback guiding the reinforcement learning. Probability and reinforcement guides the choice of tokens, there is no representation of truth.
Data are useful to the extent that they provide non-redundant relevant information for some topic of interest. Curation identifies truthful and useful information.
Most of the data provided to contemporary models is not curated and is either irrelevant or repetitive of earlier data. Human curation is very expensive. For a model to vet its own data before training on it would be a critical step forward in developing general intelligence. At the same time, I believe that it is achievable with a moderate effort. Self-curation is a necessary, but not sufficient tool for achieving general intelligence.
Credibility is an estimate of the appropriate level of trust to place in the truthfulness of an information source. This estimation requires information that is not solely in the source itself. Similarly, it cannot be based on how fluent, reasonable-sounding, or convincing the source is.
Usefulness depends on what is already represented. Useful data will be truthful and provide novel information that expands the knowledge of the system. Novel data are different from already represented data but evaluating truthfulness may depend on its similarity to existing information.
Some thoughts on where to start
Some methods already exist that could be exploited for self-curation. PageRank is one example of a method for estimating credibility. It is a recursive algorithm that uses the number of links to a page and the quality of the linking pages, to estimate the quality of the page. The general idea is that more credible pages are likely to receive more links than non-credible pages and that links from credible pages are more valuable than links from non-credible pages.
Algorithms like PageRank work reasonably well when there are links between pages, such as on the World Wide Web, but many documents do not contain explicit links. Other methods will be needed to link sources in order to use methods like PageRank.
Although PageRank and similar algorithms may be useful, they do have their limitations. These algorithms can be gamed by malicious actors. New web pages, even with high quality content, may be ignored until other pages link to them. There is very likely to be more to credibility than can be captured by links among pages. Methods will be needed to mitigate these risks.
Credibility judgments may also have to consider the motivation of page authors. A businessperson promoting her, or his product may be less credible than a review from a well-known (more) objective reviewer.
As an estimation, Estimated credibility is not guaranteed to be correct or that the information provided by the source is guaranteed to be truthful. Credibility does not depend on perfect information. Outside of formal situations, it is impossible to know with certainty whether a fact is true. There is likely to be no infallible method by which to determine the truth.
I think that it is very likely that a self-curation system will also require a method to extract propositions from text. A proposition is the smallest statement that can have a truth value. A truth value is the set of conditions under which a proposition is true. “1 + 1 = 2” is a proposition and it is true if and only if 2 really is the result of adding two ones. “Jasper is a dog” is a proposition and it is true if and only if the Jasper to which the sentence refers, actually is a dog.
This is not the place for a deep discussion of propositions. There is a long history of thought (which is likely to be useful) on just what they are and how they can be used for representation and reasoning. Propositions can be true, false, or somewhere in-between. Their truth value may be unknown. They may be useful as part of a world model.
Propositions are more abstract than natural language statements. Multiple natural language statements may have the same truth value, that is express the same proposition. “John painted the wall,” means about the same thing as “John covered the wall with paint.” The conditions under which these two sentences are true are the same for both sentences. A self-curating system would need, I think, to recognize that these two sentences are very close in meaning.
The only source of meaning for current models is the context in which words occur (distributional semantics). Words that occur in similar contexts mean similar things. The meanings of words are represented by their embeddings, but there is more to their meaning than can be represented by the current vector embeddings.
Here are six sentences in order of the distances between their large language model embeddings. Each embedding represents the statistical patterns of word use, the way that distributional semantics would specify, but their orderings do not correspond to how most people would understand their similarity structure.
The weather that day in the desert was unusually tepid for that time of year.
The weather that day in the desert was unusually cool for that time of year.
The weather that day in the desert was unusually cold for that time of year.
The weather that day in the desert was unusually scorching for that time of year.
The weather that day in the desert was unusually warm for that time of year.
The weather that day in the desert was unusually hot for that time of year.
The sentences range from “cold” to “scorching,” but the embeddings range from “tepid” to “hot,” with “scorching” between “cold” and “warm.” People clearly know more about the meanings of words than is apparently captured by the embeddings and the utterance patterns. A self-curating computer may have to know more as well.
The same natural language statement may have multiple truth values. For example, the sentence, “The police would not stop drinking,” could be true if the police were drinking and refused to stop. Alternatively, it could be true if the police were unwilling to stop other people from drinking. A self-curating model may need an embedding system for the truth value of propositions, not just for the probability of words appearing in context.
Identifying novel truthful information may present additional challenges. It may require reasoning about the probability of a proposition being true given related information. For example, if credible sources provide information that the Prime Minister of Japan has resigned, then it raises the likelihood that a new person is the current Prime Minister. Shigeru Ishiba replaced Fumio Kishida in October 2024.
It will probably be necessary to put together a curation benchmark. It takes a substantial effort to curate a data set and it would be useful to be able to amortize that effort over many investigations. Succeeding on distinguishing credible from non-credible data sources would not be sufficient to say that self-curation has succeeded, benchmarks can be hacked. They can be solved without accomplishing their intended function. But, it would help to make more rapid progress during the initial stages of development without having to invest in curation each time.
It has not escaped my attention that there may be alternative methods to those I am suggesting. These suggestions represent how I have thought about the problem, but there may also be other ways to accomplish self-curation.
Many problems remain to be solved to produce an AI model that can critically assess the credibility, truthfulness, and usefulness of information. At a minimum it will require a model that can represent these qualities. Applying these same assessments to the model’s output would help to reduce the errors (hallucinations) that currently plague these systems. I do no expect that meeting this challenge will be sufficient to produce general intelligence, but I do think that it is a necessary part.
Has anyone developed LLMs based on spiritual and philosophical texts? It would be fascinating to have these different models then talk together along with us humans.
I did some experimenting with having Machiavelli debate Collins on leadership https://x.com/christo35065901/status/1877510056666620212?s=46